Update: We’ve also rolled this functionality into our Creare SEO Magento Extension which is available for free on Magento Connect and also featured within the book “Magento Search Engine Optimisation” – win a free copy.
A common problem in many websites, Magento included, is the duplication of parameter-based pages. The most common occurrence of this within Magento tends to be Layered Category pages – when an attribute filter is active.
Google (and other search engines) tend to treat parameter-wielding URLs as separate pages – mainly due to the vast amount of websites that still use parameters to serve all of their standard web pages (domain.com/?pageid=753 look familiar?).
As the content of our category pages only differs very slightly when these filters are active – we don’t really want Google to cache them as separate pages – especially if we have a lot of text content in our category description. The duplication of the category description could lead to duplicate content penalties being imposed on our category page/website in general.
There are a few ways to combat this problem – some work really well, some don’t. I’m a personal fan of using every trick in the book to get the desired result – and I’d urge you to do the same – mainly due to a few of these techniques being inconsistent with persuading Google to de-index (or not index in the first place) these “duplicate pages”.
The main tricks tend to be:
- Canonical Tag
- Robots.txt file
- Google Webmaster Tools URL Parameters
- Meta Robots NOINDEX
Here’s a breakdown of the positives and negatives of each of these techniques.
Canonical Tag
The canonical tag is already built into later versions of Magento (I believe 1.4 onwards?) and you can find the settings to turn it on within System > Configuration > Catalog > Search Engine Optimisation.

What this feature will do is place a canonical tag within yourelement. Canonical tags basically tell Google where the “master” version of the page is – and to ignore the current page if it’s different to it’s canonical URL.
How does this affect our category filter pages? Well, on all of our category filter pages (Category URL’s with the ?cat=3 for example) this canonical tag should be enabled – telling Google that this filter page is really just a copy of the master category and not to penalise the page or the site because of it.
The main issue I have found with the canonical tag is that it doesn’t work consistently – especially for categories. Product pages I have found work extremely well with the canonical tag (usually telling Google to cache the product URL as domain.com/product-url.html rather than with categories) but even with the same functionality enabled on category pages – I receive duplicate listings in the SERPs – possibly because of those parameters.
Robots.txt file
The robots.txt file has pretty much been around since search engines were invented and is one of the most useful text files you’ll find on any website.
The main purpose of the robots.txt file is to let search engines know which pages they can access and which areas they can’t.
Within a robots.txt file you can specify search engines to ignore our parameter based pages simply by adding the following line:
Disallow: /*?*
This will disallow any URL with a question mark anywhere inside it. Obviously this is useful for our category filters problem – but if you want to use this you really need to make sure that areas of your website are not relying on parameters for any of your vital pages that you want cached by the search engines.
The main problem I have found with robots.txt files is that they disallow search engines from VISITING the page again. They don’t ask the search engine to de-index / remove from it’s database your ‘already cached’ duplicate pages – at least not immediately. So really you should use the robots.txt technique as soon as you launch your website – otherwise you’ll still end up with duplicate pages in the SERPs for some time.
Google Webmaster Tools URL Parameters
Built into Google WMT is a feature called URL Parameters that supposedly allows you to specify what your parameters are doing to a page. It looks like it’s engineered toward helping site owners alleviate a few of the problems caused by parameters that are simply adapting the content of the page to help with usability.
You can find this tool within your WMT dashboard > Crawl > URL Parameters.
There’s a warning within Google WMT notifying users that placing the wrong parameters could result in many pages being removed from it’s search results – meaning that unlike the robots.txt, this technique may actually help to remove those duplicate pages.
I’d recommend (if you wish to go down this route) simply to add your primary attribute codes that you have set up in your layered navigation. For instance – the following URL parameters have worked for our website:
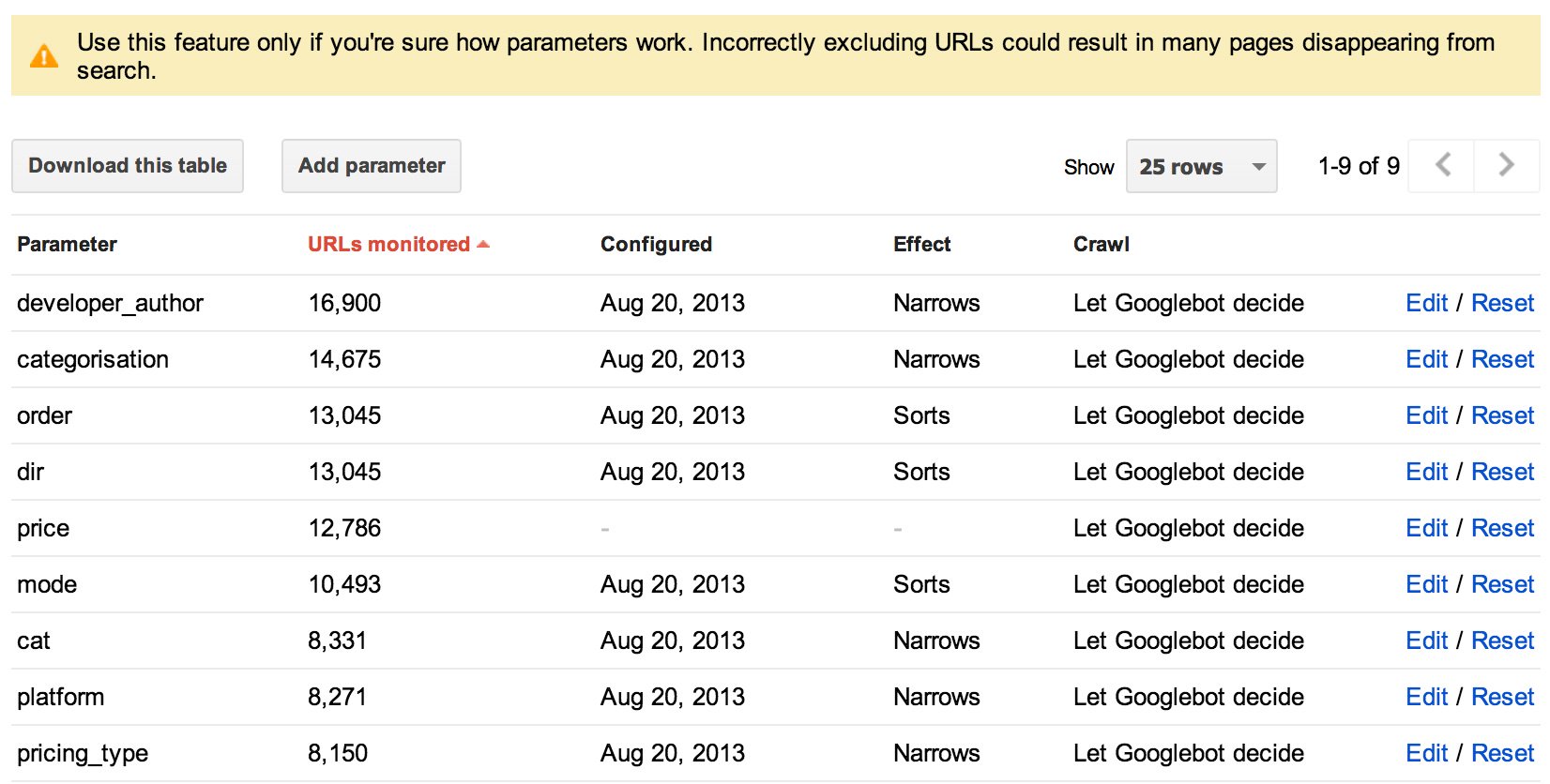
As you can see – there’s a lot of URLs featuring those parameters – and our website doesn’t even boast an extensive product catalogue!
Meta Robots NOINDEX
Every Magento developer will be aware that Magento comes with it’s own Meta Robots tag – when a site is live it normally looks like this:
<meta name="robots" content="INDEX,FOLLOW" />
When a website is in development this is normally set to NOINDEX,NOFOLLOW – basically blocking the website from Google happening across it.
I’m a big fan of the robots meta tag – however I must confess that I do not believe it to be 100% bulletproof – all too often I’ve seen development domains in Magento being cached by Google – simply due to the robots.txt file being missing.
That said, the NOINDEX value has certainly been used to great effect in the SEO world for telling Google to de-index pages – and it certainly works inside a Magento installation too.
Normally, to implement the NOINDEX tag you would do it within the DESIGN tab of either a category/page or product.
For instance if I wanted to NOINDEX a category I’d go ahead and add the following code into the custom design tab (custom layout xml):
<reference name="head">
<action method="setRobots">
<value>noindex,follow</value>
</action>
</reference>
This will replace the site-wide meta robots tag just for this category – HOWEVER is this really what we want? I don’t think so – we still want our category to be indexed, we only want this tag to be replaced when our category filters are active.
The above XML adjustment is useful though for de-indexing/blocking specific products and pages that you want to remain active but non-indexable by search engines. Again, blocking via robots.txt is always recommended – but if it’s already been cached – implement this code as well.
Adding Meta Robots NOINDEX for Parameter-wielding Categories
So how can we implement this NOINDEX value only when a category filter is active? Well, the answer is by using an Observer and a little bit of PHP.
This implementation will form part of our Magento SEO extension that will be in place later this year but for now here are the important parts of the code.
To create this as an extension you simply need to create your module declaration file, a config.xml and an Observer.php all within the appropriate folders (for a more detailed explanation of this please see this post).
Within the config.xml we need to track our observer:
<frontend> ...... <events> <controller_action_layout_generate_xml_before> <observers> <noindex> <type>singleton</type> <class>noindex/observer</class><!-- replace with your module name --> <method>changeRobots</method> </noindex> </observers> </controller_action_layout_generate_xml_before> </events> ......
In our Observer.php we need to add the following code:
public function changeRobots($observer)
{
if($observer->getEvent()->getAction()->getFullActionName() == 'catalog_category_view')
{
$uri = $observer->getEvent()->getAction()->getRequest()->getRequestUri();
if(stristr($uri,"?")): // looking for a ?
$layout = $observer->getEvent()->getLayout();
$product_info = $layout->getBlock('head');
$layout->getUpdate()->addUpdate('<reference name="head"><action method="setRobots"><value>NOINDEX,FOLLOW</value></action></reference>');
$layout->generateXml();
endif;
}
return $this;
}
What the above will do is create an observer that will check to see whether we are on a category view page. If we are it will then check to see if we have a ? in the URL. If we do then we inject our XML layout changes directly into the page – swapping the meta robots value to NOINDEX,FOLLOW.
Conclusion & Findings
It’s hard to pin down a particular technique to a particular result – especially when search engine algorithms change all the time – as does website content. The best example I can give you is a short graph showing our index status across a period of months from when we launched our new website.
Please bear in mind that creare.co.uk is not the largest website in the world – only around 500 pages. Have a look and see how many pages Google believe we had – all due to duplicate pages via parameters!
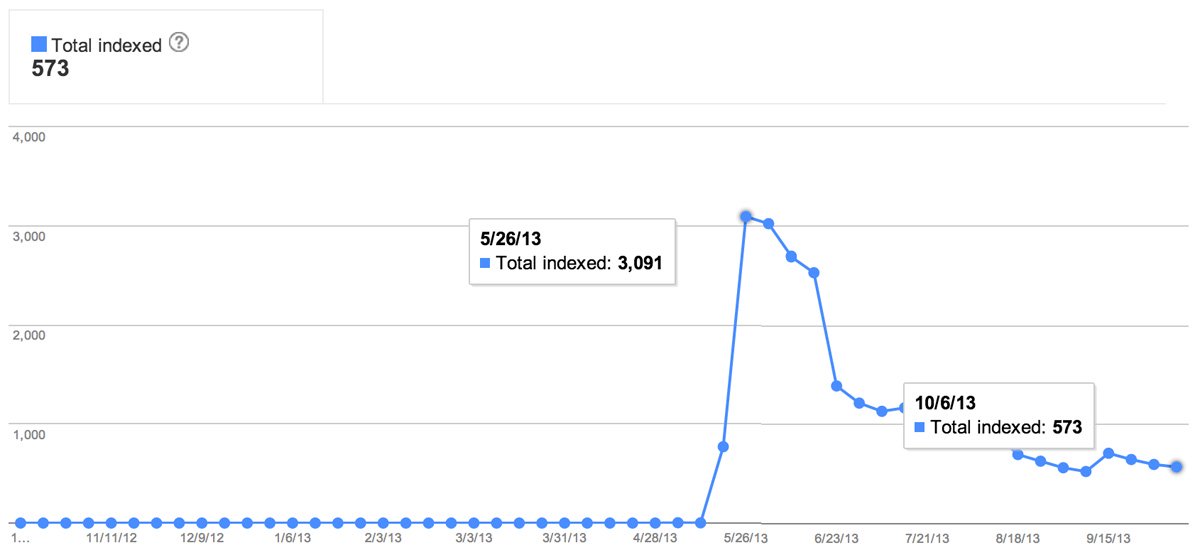
You can definitely see the dramatic effect our changes (all of those techniques above) have had on our page index count with Google – we now tend to have only one version of our main pages in the SERPs (though to be honest there’s still a few that are still to be removed) rather than hundreds of copies.
A couple of important points to take away if you’re planning on implementing any of the above:
- Be very careful – try not to get your main web pages de-indexed!
- Try using one or more of the techniques at the same time – never rely on one method to solve all issues
- Always use the canonical and robots.txt files and make sure you do these first
- Use the meta NOINDEX method if you’re already suffering with duplicate listings in Google
- If you need to use the NOINDEX method – make sure you temporarily stop your robots.txt from doing the same thing for the same pages – otherwise Google will not revisit the page and see your new NOINDEX tag!
- Give the URL Parameters in Google WMT a go – and let me know if you see any notable changes!
Other than that, I think it about covers it. Thanks for visiting – any questions please leave them below and I’ll do my best to answer them. If you enjoyed this post on Magento duplicate content issues you may like James’ post on HTTP vs HTTPS duplicate content troubles.