
There were a number of great talks from BrightonSEO this year with the standard getting better and better each year. Instead of doing a large round up of every single talk at the conference I wanted to give you some key points from a technical SEO and SEO R&D point of view as this is my area of interest.
Key takeaways
- Use Google Tag Manager to Implement JSON-LD.
- Google has the possibility to introduce factual accuracy as a ranking factor.
- Having a Mobile-Friendly tag in Google doesn’t mean that your website is mobile friendly but it is the best sign from Google that we currently have.
- Twitter cards with large image as appose to small images increase CTR by 50%.
- Design mobile first not as an after thought.
Favourite Speaker of the Day
My favourite speaker award has to go to Jon Earnshaw (@jonearnshaw) and his talk on Search Cannibalisation, it gave great insight into simple problems with internal duplication that cause poor performance.
Summarise Brighton SEO in 5 words
Great Delivery of Actionable Insights
Quote of the day
“It’s the era of the personal assistant, whether it’s Cortana, Google Now or Siri, search is changing.†– Mark Thomas (@deepcrawl)
Roundup of best talks of the day
Cannibalisation of Search -Â Jon Earnshaw (Pi Datametics) (View Slides)
One of the best talks on the day came from Jon Earnshaw and his talk on the cannibalisation of search. Jon focused on the drop in rankings for multiple websites and the reason behind that being based on Cannibalisation of Search which can come in 4 forms, Internal Conflict, Sub-Domain Conflict, International Conflict and Semantic Flux. The main one of them being that of Internal conflict, the scene was was set with a website that had seen a suspicious flux in rankings followed by a drop. When looking into this fluctuation in more depth you could see that the drop had coincided with another page from the same website being selected to represent that keyword, this was down to internal duplication. The different colours on the below graph represent different web pages.
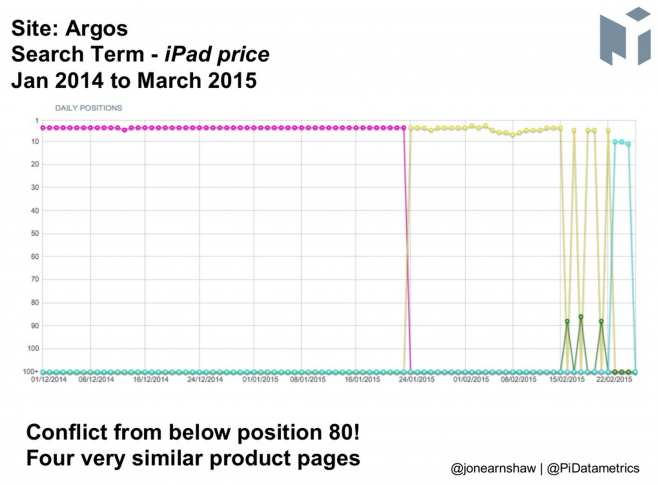
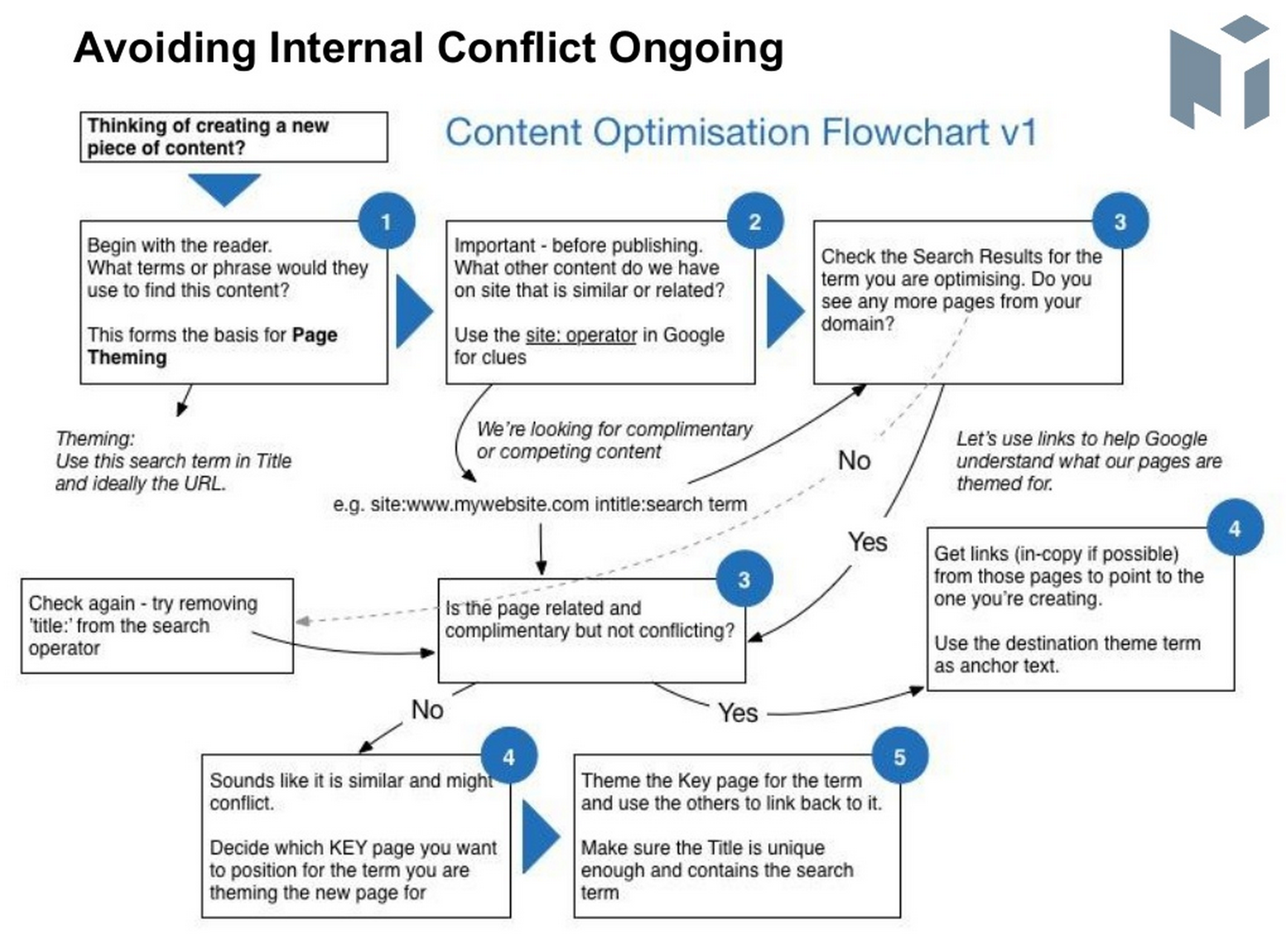
It is a problem that is easy to solve, ensure that you let Google know which page you wish to rank for the keyword either by internal linking or canonical links. Jon also shared a great flow chart to follow to stop you from creating duplication going forward.
Advanced Competitive Analysis – Rob Bucci (STAT Search Analytics) (View Slides)
Rob took a great approach to the competitive analysis process using Argos, Amazon and eBay as his client and competition websites. To complete the analysis he used the following dataset;
- 4715 Commercial Queries based around TV’s
- These were segmented into Brand, Screen Size, Screen Type and HD Format Queries
- All commercial intent keywords
- All keyword data was UK focused
From this data the keywords were weighed based on where the website was ranking against its search volume;

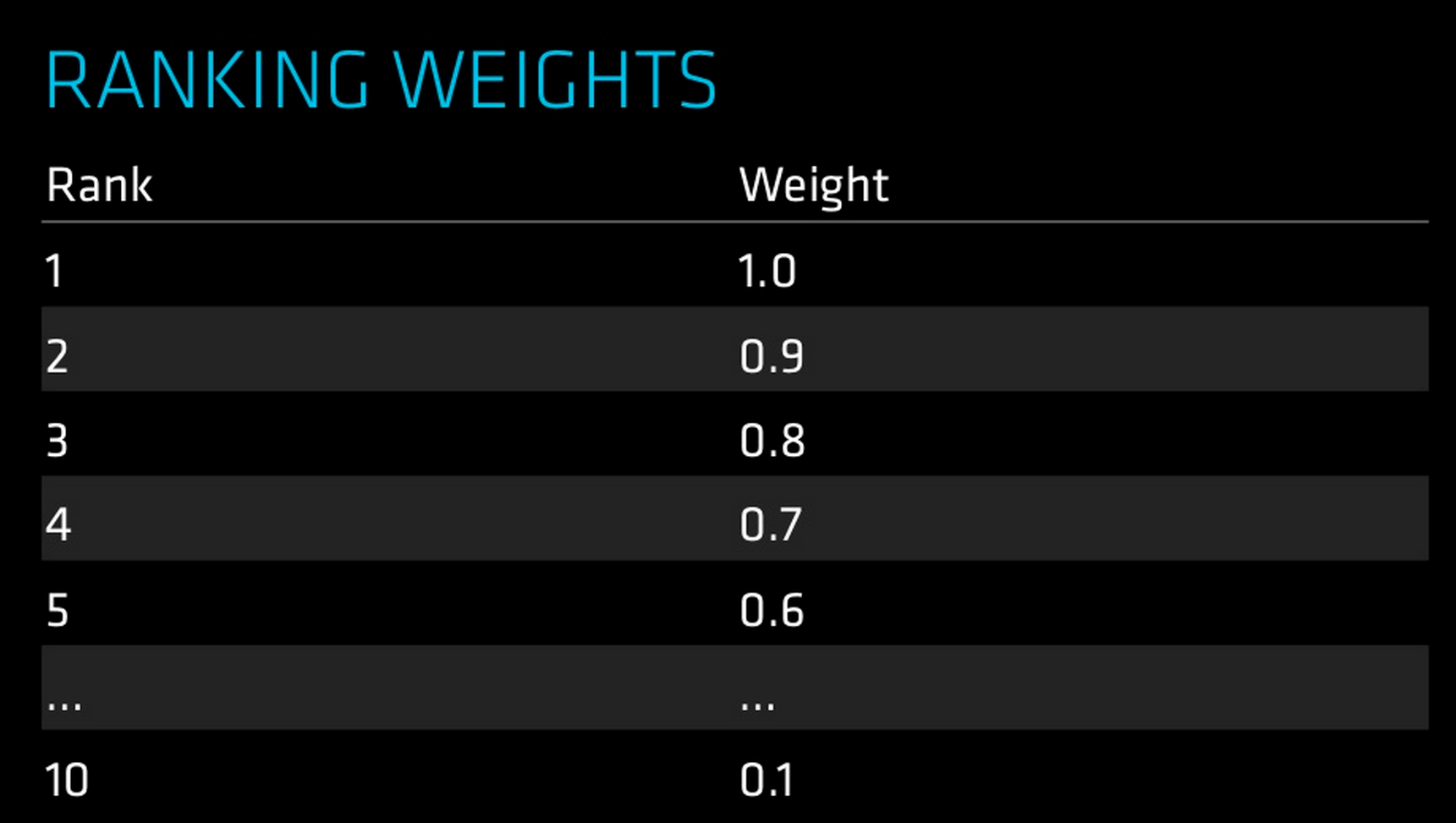
Rob then went onto calculating the websites scores across different segments based on this information, I have listed the slides above if you wish to see the results in more detail. The conclusion from this experiment was that you should push for the 2nd most valuable keyword segment as it is easier to achieve higher rankings. From the analysis he also concluded that you should also focus on ranking your page that has the best User Experience, ensuring that you complete research on what types of pages rank for your keywords as this can give you some insight into the type of page Google is looking for.
JSON-LD -Â Kirsty Hulse (Found) (View Slides)
Kirsty gave a great talk on JSON-LD and the reasons for using it, JSON-LD is quickly becoming a preferred alternative to microdata due to it being a lot easier to setup on a page without having to alter multiple elements on a page. During the talk Kirsty revealed that just 0.3% of domains on the web are using any form of schema mark-up which is a very small amount and also a great opportunity for many webmasters to have the advantage over their competition. A resource for you to use is the JSON-LD playground, not your usual playground with sun, birds and butterflies, the JSON-LD playground allows you to test your markup and see what elements need to be updated there is also a large amount of documentation on the json-ld.org website for you to sink your teeth into.

Now if you work in an agency you will often find that access to websites can change very quickly and to allow you to have control to make changes to JSON-LD when required you can setup JSON-LD through Google Tag Manager. Google Tag Manager installs just like Google Analytics does but gives you access to be able to add JSON-LD into the header of the website. You can also setup Google Analytics and complete a multitude of other tasks through the tag manager so it is a great addition to your SEO toolkit.
How to Spot a Bear -Â Tom Anthony (Distilled) (View Slides)
Not a newcomer to the SEO stage Tom gave a great insight into the basics of Machine Learning from an SEO perspective, including insight into the difficulties that Google faces when trying to learn from the data that it currently stores. Google announced a little while ago that it had created software that could analyse an image and return a natural description of what was shown in the image. This itself was cool and Tom went on to state that they had also completed this for Videos. Now for SEO this update seems insignificant, but if your web page is built up of a large number of stock images just to “fill the spaceâ€Â and these images are not related to the content on the page, Google could mark your website down on relevancy score. Google’s main focus is to understand the web and the content within it, this allows it to return the most relevant results for a search query. One of the largest updates based around context is Hummingbird. Hummingbird was built in such a way that it allows for smaller updates to be rolled out without a large overhaul of the algorithm. This is something that will affect the SEO industry with the possibility of more updates rolling out unnoticed.
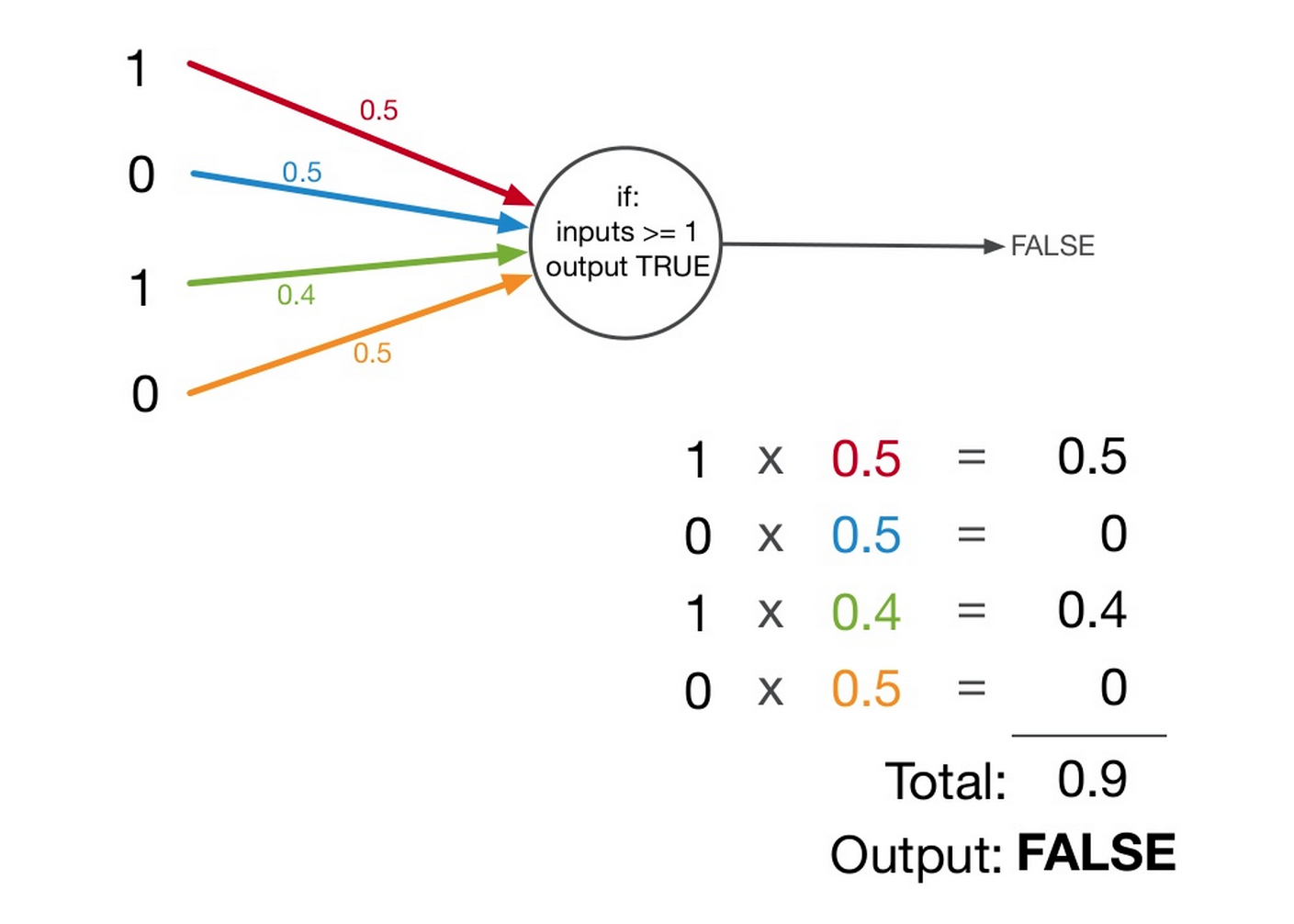
Another topic on discussion was Knowledge Graph and Google’s quest for facts. Google builds up its Knowledge Vault with information that it can gain whilst crawling websites, Google then uses other websites to cross reference facts and decide on whether a fact stated is accurate or not. What does this mean for SEO? with the ability to cross reference facts with other websites Google can tell if your web page is factually correct or not based against other information that it has gained from crawling. It could in the future use factual accuracy as a ranking factor, which makes sense as Google  doesn’t want to supply incorrect information to its searchers.
All in all Brighton SEO didn’t disappoint yet again and continues to be the best free conference in the UK!